- Published on
Building RAG Chatbots: Bridging LLMs with Private Data
- Authors

- Name
- K B Rahul
- @kbrahul_
Building RAG Chatbots
Large Language Models (LLMs) are powerful but limited to their training data. They hallucinate when asked about recent events or private documents. Retrieval-Augmented Generation (RAG) solves this by grounding the LLM with external context.
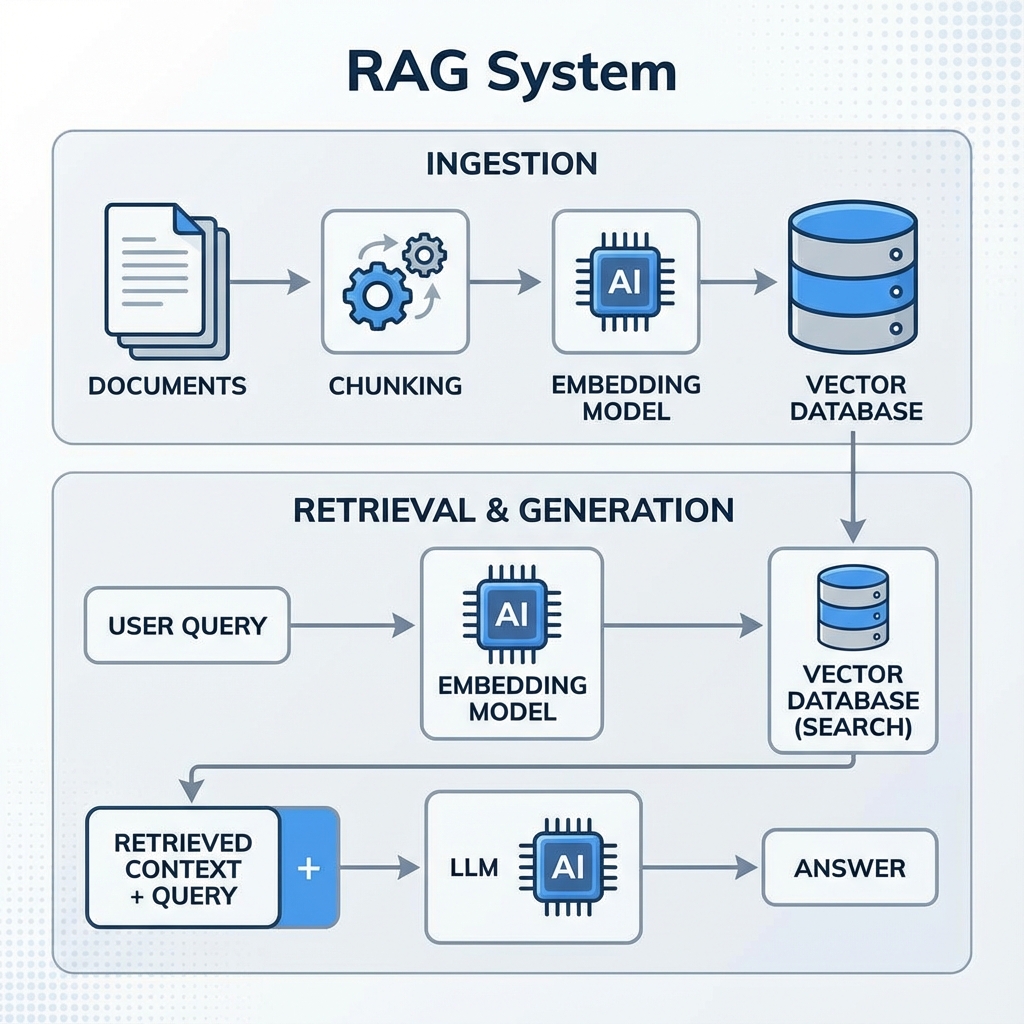
The RAG Architecture
- Ingestion: Documents are split into chunks and embedded into vectors using an embedding model (e.g., OpenAI text-embedding-3, HuggingFace models).
- Storage: Vectors are stored in a Vector Database (e.g., Pinecone, Milvus, Chroma).
- Retrieval: When a user asks a question, it is also embedded. The database finds the most similar chunks (semantic search).
- Generation: The retrieved chunks are passed to the LLM as "context" along with the user's query.
Chunking Strategies
How you split your text matters.
- Fixed-size chunking: Splitting by character count (e.g., 500 chars). Simple but breaks context.
- Recursive chunking: Splitting by separators (paragraphs, newlines) to keep semantic units together.
- Semantic chunking: Using an embedding model to detect topic shifts and chunk accordingly.
Advanced Retrieval Techniques
Hybrid Search
Semantic search (vectors) is great for concepts, but Keyword search (BM25) is better for exact matches (e.g., part numbers, names). Hybrid Search combines both scores to get the best of both worlds.
Re-ranking
Vector search is fast but approximate. A Cross-Encoder (Re-ranker) is a slower but more accurate model that takes the query and the retrieved document pairs and outputs a relevance score. We use it to re-order the top 10-20 results from the vector search before sending the top 3-5 to the LLM.
Code Snippet: Simple RAG Flow
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# Initialize components
embeddings = OpenAIEmbeddings()
db = Chroma(persist_directory="./chroma_db", embedding_function=embeddings)
llm = OpenAI(temperature=0)
# Create chain
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=db.as_retriever())
# Ask question
query = "What does the company policy say about remote work?"
print(qa.run(query))
Conclusion
RAG is the standard pattern for enterprise LLM applications. It provides accuracy, explainability (citations), and data privacy.