- Published on
NLP and Transformers Explained: Attention is All You Need
- Authors

- Name
- K B Rahul
- @kbrahul_
NLP and Transformers Explained
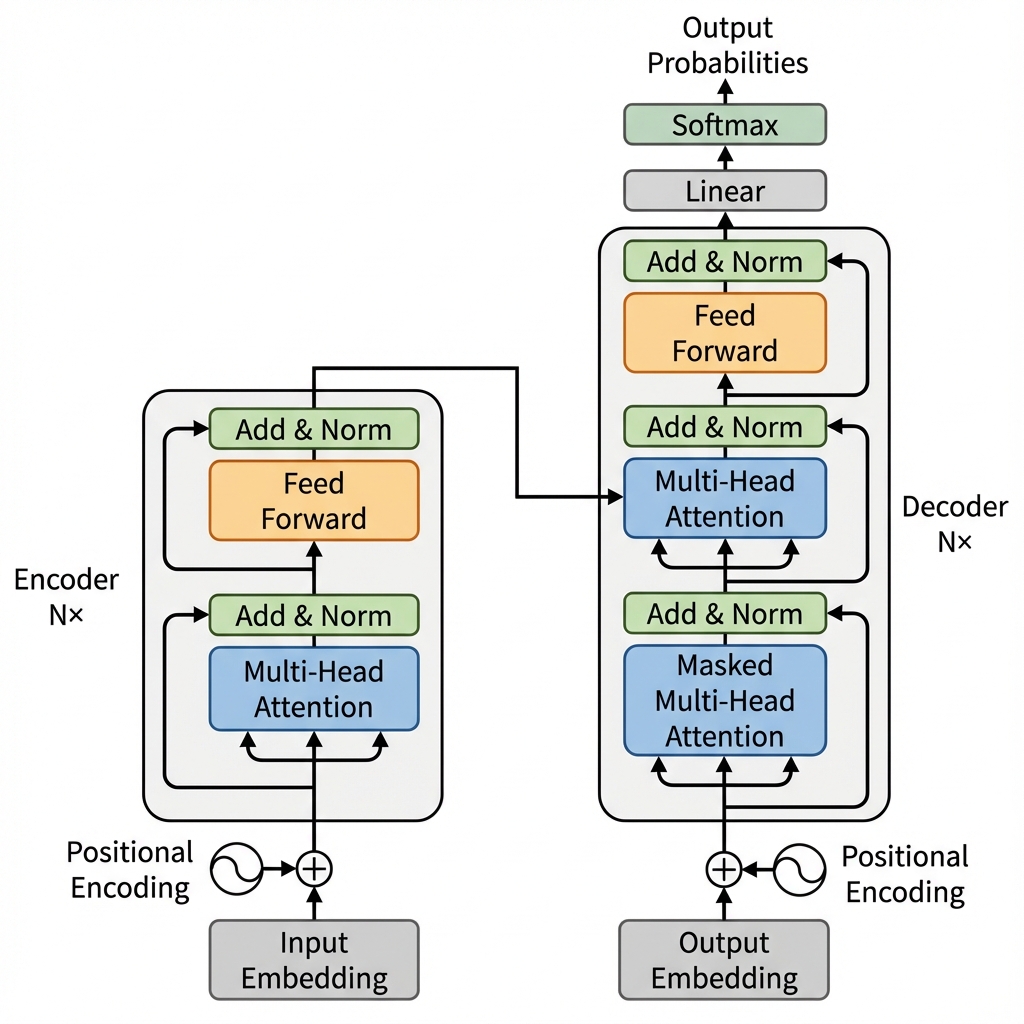
The "Transformer" architecture, introduced in the paper "Attention Is All You Need" (2017), revolutionized Natural Language Processing (NLP). It replaced Recurrent Neural Networks (RNNs) and LSTMs as the standard for sequence modeling.
The Core Innovation: Self-Attention
Before Transformers, models processed words sequentially (one by one). This made it hard to capture long-range dependencies. Self-Attention allows the model to look at all words in a sentence simultaneously and decide which ones are relevant to each other.
The Math of Attention
The mechanism can be described as a retrieval system:
- Query (Q): What we are looking for.
- Key (K): What we match against.
- Value (V): The information we extract.
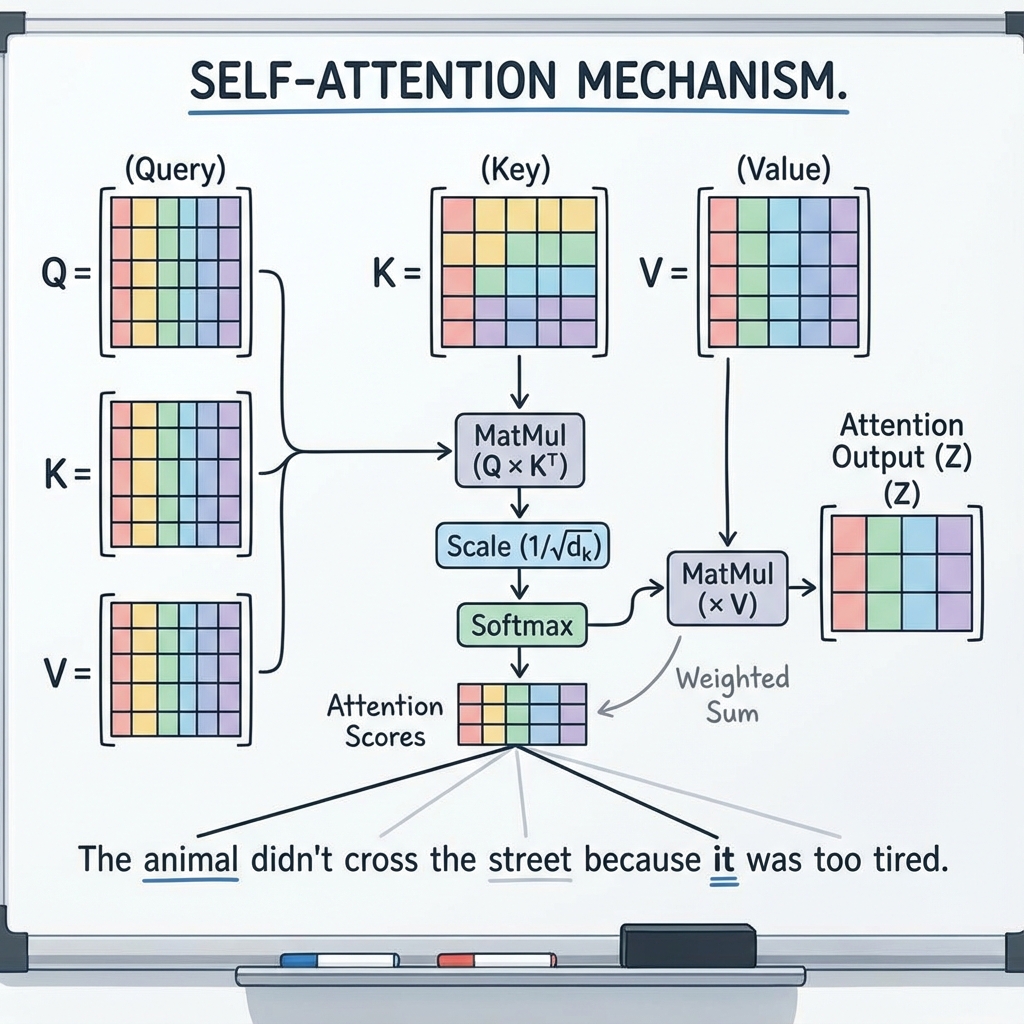
The attention score is calculated as:
- : Computes similarity between the Query and all Keys (dot product).
- : Scaling factor to prevent gradients from vanishing.
- Softmax: Normalizes scores to probabilities (sum to 1).
- : Weighted sum of Values based on the scores.
Multi-Head Attention
Instead of doing this once, we do it multiple times in parallel ("heads"). Each head can focus on different aspects of language (e.g., one head focuses on syntax, another on semantics).
Architectures: Encoder vs. Decoder
The original Transformer had both an Encoder and a Decoder. Modern LLMs often use just one part.
1. Encoder-Only (e.g., BERT)
- Bidirectional: Sees context from both left and right.
- Masking: Uses "Masked Language Modeling" (MLM) where random words are hidden and the model must guess them.
- Use cases: Classification, Named Entity Recognition (NER), Sentiment Analysis.
2. Decoder-Only (e.g., GPT, Llama)
- Unidirectional: Predicts the next token based only on previous ones (Causal Language Modeling).
- Use cases: Text generation, code completion, creative writing.
3. Encoder-Decoder (e.g., T5, BART)
- Hybrid: Encodes input text and generates output text.
- Use cases: Translation, Summarization.
Scaling Laws
We've learned that model performance scales predictably with:
- Parameter Count (N)
- Dataset Size (D)
- Compute (C)
This realization (Kaplan et al., 2020) led to the "arms race" of Large Language Models (LLMs), pushing from millions to trillions of parameters.
Conclusion
Transformers have become the foundation of modern AI, extending beyond NLP to Computer Vision (ViT) and Audio. Understanding attention is key to understanding the current AI landscape.