- Published on
Deep Dive into Audio Forensics: Detecting Manipulation in the Age of AI
- Authors

- Name
- K B Rahul
- @kbrahul_
Deep Dive into Audio Forensics
In the era of Generative AI, the ability to synthesize realistic human speech has become accessible to everyone. While this empowers creators, it also poses significant security risks. Audio forensics is the science of analyzing audio recordings to establish their authenticity and integrity.
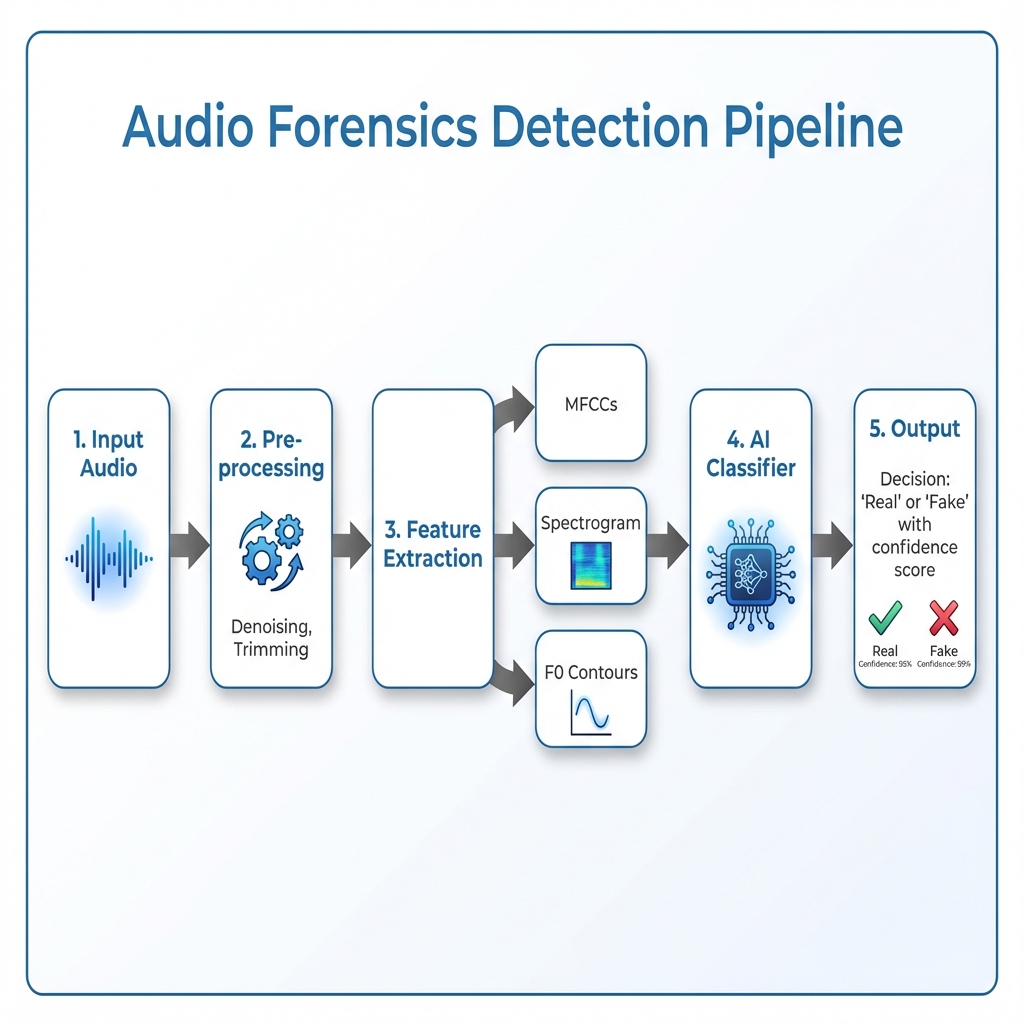
The Challenge of Deepfakes
Deepfake audio, or "voice cloning," uses deep learning models to replicate a target speaker's voice. Models like Tacotron 2, VITS, and more recently, zero-shot voice cloning systems (e.g., VALLE, ElevenLabs), can generate convincing audio from just a few seconds of reference material.
The core challenge is that these models are trained to minimize the perceptual difference between real and fake speech. However, they often leave behind subtle statistical traces that are invisible to the human ear but detectable by machines.
Key Forensic Techniques
1. Spectral Analysis
One of the first steps in audio forensics is analyzing the spectrogram—a visual representation of the spectrum of frequencies of a signal as it varies with time.
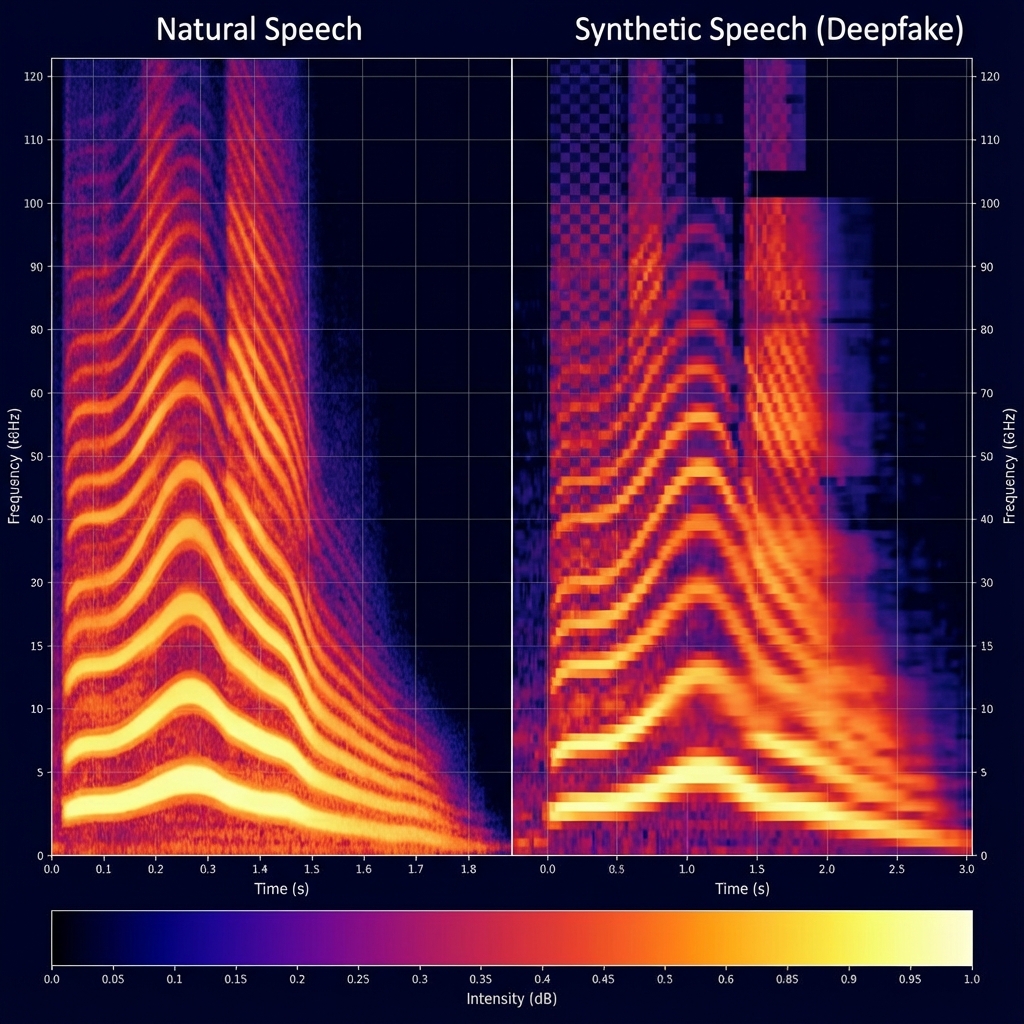
As shown in the comparison above:
- Natural Speech: Exhibits a rich harmonic structure that decays naturally. The transition between phonemes is smooth.
- Synthetic Speech: Often exhibits artifacts in the high-frequency range (above 8kHz or 16kHz, depending on the sampling rate of the vocoder). You might see abrupt cut-offs or "checkerboard" patterns resulting from the upsampling layers in GAN-based vocoders.
2. Phase Continuity
In natural speech, the phase of the audio signal evolves continuously. Splicing (copy-pasting parts of audio) or synthesis often disrupts this continuity. Algorithms can detect these phase discontinuities even if the amplitude spectrogram looks perfect.
3. The ASVspoof Challenge
The academic community organizes the ASVspoof (Automatic Speaker Verification Spoofing and Countermeasures) Challenge to benchmark detection systems. It covers:
- Logical Access (LA): TTS and Voice Conversion attacks.
- Physical Access (PA): Replay attacks (recording a voice and playing it back).
- Deepfake: Detecting fully synthetic audio.
Top-performing systems often use RawNet2 or LFCC-GMM (Linear Frequency Cepstral Coefficients with Gaussian Mixture Models) to capture artifacts that MFCCs (Mel-frequency Cepstral Coefficients) might miss.
4. ENF Analysis (Electric Network Frequency)
The Electric Network Frequency (ENF) is a unique hum generated by power grids (50Hz in Europe/Asia, 60Hz in US). This hum is often embedded in recordings made near power lines or plugged-in devices. By extracting the ENF signal and comparing it to historical grid data, forensic analysts can verify the time and location of a recording.
AI-Based Detection Code Example
Modern forensics employs AI to catch AI. Here is a conceptual example of how to extract features for a simple detector using Python and librosa.
import librosa
import numpy as np
from sklearn.svm import SVC
def extract_features(audio_path):
"""
Extracts MFCCs and Spectral Contrast features.
"""
y, sr = librosa.load(audio_path)
# Mel-frequency cepstral coefficients (MFCCs)
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
mfcc_mean = np.mean(mfccs.T, axis=0)
# Spectral Contrast (often captures vocoder artifacts)
contrast = librosa.feature.spectral_contrast(y=y, sr=sr)
contrast_mean = np.mean(contrast.T, axis=0)
return np.concatenate([mfcc_mean, contrast_mean])
# Conceptual training loop
# X_train = [extract_features(f) for f in training_files]
# y_train = [0 if 'real' in f else 1 for f in training_files]
# clf = SVC()
# clf.fit(X_train, y_train)
Conclusion
As AI generation tools evolve, so must our detection methods. Audio forensics is a cat-and-mouse game. While current detectors are effective against known models, "zero-day" deepfakes (generated by new, unseen architectures) remain a significant threat. The future lies in watermarking and provenance technologies (like C2PA) to authenticate content at the source.